Pourquoi doit on bidouiller Hubic pour utiliser un client swift ?
- OpenStack/Swift, habituellement, comment ça marche ?
- Pourquoi OVH a décidé de faire autrement ?!
- Pré-habilitation des applications auprès d’Hubic
- Définir les autorisations d’accès de l’application
- Demander un accès temporaire à l’API Hubic de l’utilisateur
- Utiliser l’API Hubic … dans quel but ?
- Synthèse
- La gateway Hubic/Swift
Après m’être intéressé à l’offre de stockage d’Hubic et son tarif formidable (10 tera-octets pour 50 euros par an !) et avoir appris que "Hubic ce n’est pas de l’OpenStack standard", j’ai voulu comprendre pourquoi.
Pour accéder aux stockage OpenStack, on utilise un client Swift quelconque : swift pour la ligne de commande, et SwiftExplorer ou CyberDuck pour une version graphique.
Mais pour accéder à Hubic, on ne peut pas utiliser directement un client Swift directement. Je voulais comprendre la manière dont les choses s’articulent, donc ce billet d’aujourd’hui est un récapitulatif de ce que j’ai trouvé.
OpenStack/Swift, habituellement, comment ça marche ?
Comme toujours quand les choses sont sécurisées, l’accès à une resource se fait toujours en deux étapes : d’une part l’authentification pour vérifier que celui qui demande l’accès a le droit d’atteindre la resource, et ensuite l’accès à la resource proprement dite.
En conséquence, un appel "swift" va générer deux opérations successives :
-
La première opération est l’authentification (la partie jaune) sous la forme d’un appel à l’API Auth v1, où on donne des informations d’identification, et où on récupère (en orange) le "périphérique de stockage" (endpoint) ainsi qu’un moyen d’authentifier l’accès (token) à cette resource.
-
La deuxième opération est la réalisation de l’opération demandée (en rouge) : on utilise la commande, le token, et le périphérique, pour effectivement faire faire ce qu’on veut (lister les fichiers, uploader, downloader, supprimer…) via un appel à l’API Object Storage v1.
On voit ça sur le diagramme ci-dessous :
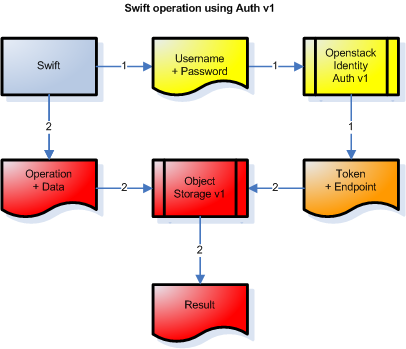
Dans tous les cas, c’est "juste un protocole". N’importe quelle application qui respecte ce protocole peut accéder à toutes les resources accessibles offerte via ce protocole.
Pourquoi OVH a décidé de faire autrement ?!
La raison se trouve dans la dernière phrase du paragraphe ci-dessus : à la première lecture, on peut se dire "c’est super, c’est générique". Mais justement, c’est générique, et c’est bien là le problème :
D’une part, "n’importe quelle application peut accéder", ça signifie aussi que :
-
une application légitime peut accéder, mais qu’une application illégitime peut accéder aussi, tant qu’il a les logins/mots de passe.
-
qu’une application légitime qu’on arrête d’utiliser, ou qui devient "encombrante/gênante", ne peut pas être empêchée d’accéder aux données
D’autre part, "peut accéder à toutes les resources", ça signifie aussi que :
-
dans le cas où plusieurs resources sont accessibles (un peu comme si on avait plusieurs disques durs), alors tous peuvent être accédés par l’application
-
imaginons que l’application ne fasse pas que du stockage (par exemple aussi du chat), et bien il est impossible de "supprimer" l’autorisation d’accès au stockage sans supprimer tous les autres droits d’accès.
Pour finir, et ça c’est presque le plus importat : comme tout accès aux services d’Hubic se faisant par un username/password, si on ouvre l’accès à vos resources auprès d’une application tierce, ces applications et programme tierces devraient "de base" connaître/utiliser/stocker vous informations de connexion de l’utilisateur pour accéder au service. Et ça c’est pas bien du tout…
En conséquence, OVH a choisi :
-
d’une part que chaque application soit habilitée explicitement par ses clients, afin de pouvoir par exemple révoquer l’accès de cette application aux infrastructures.
-
d’autre part que chaque utilisateur puisse autoriser (et être au courant, et ait la capacité de révoquer) l’accès à ses propres données pour l’une ou l’autre des applications compatibles Hubic
-
pour finir OVH a souhaité être le seul capable d’accéder aux informations de connexion de l’utilisateur, dans le but d’assurer au mieux la sécurisation de celles-ci et de réduire les risques de fuite et de mauvais usages
En bref, ces changements permettent de contrôler l’accès des applications aux resources Hubic de l’utilisateur et de sécuriser les informations client. Mais forcément, ça va compliquer un peu la tâche…
Pré-habilitation des applications auprès d’Hubic
Hubic demande d’abord la pré-habilitation des applications souhaitant utiliser les services d’Hubic : si vous voulez faire une application (un client mobile, une application web, n’importe quoi) qui utiliserait l’API d’Hubic, il faut pré-habiliter cette application dans l’infrastructure Hubic.
C’est réalisé en se connectant sur son compte hubic, en allant dans "mon compte", en allant dans la section "developpeur", en ajoutant une application (nom, et URL d’accès à cette application), comme illustré dans les images ci-dessous :
Etape 1: aller dans son compte Hubic
Etape 2: aller dans la section developpeur
Etape 3: ajouter une application

Etape 4: relever les informations de l’application
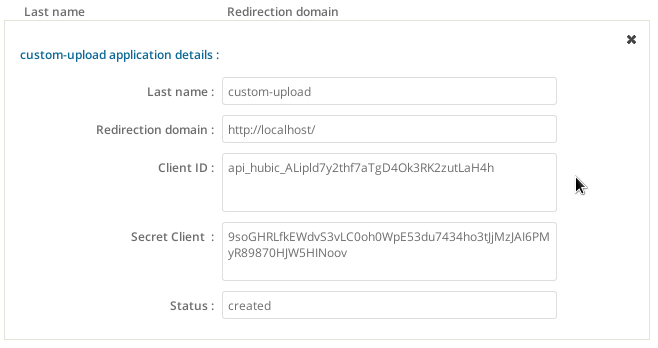
Information : j’ai modifié toutes les infos dans Firefox (via Inspect Element des extensiosn Web Developer) avant de faire les captures d’écran … ça ne sert à rien d’essayer d’utiliser les informations affichées dans les captures d’écran :-)
En synthèse, ça donne ça :
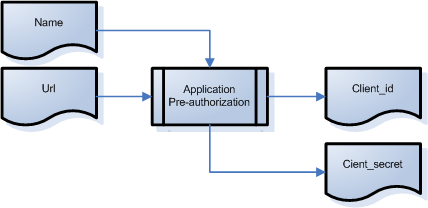
Ce qu’on obtient sont :
-
le
Client ID(api_hubic_ …) qui est un ID de l’application "client au sens d’Oauth", c’est à dire une application qui souhaite accéder à l’API Hubic -
le
Secret Clientest une clé qui va permettre de valider que cette application est bien qui qu’elle prétend être
A partir de ce moment là, cette application "existe" au sein d’Hubic, et pourrait dans l’absolu être utilisée par tous les utilisateurs du service.
Définir les autorisations d’accès de l’application
Toujours par rapport à l’explication de tout à l’heure, ce n’est pas parce que l’application "existe" et qu’elle respecterait un "protocole" qu’elle est effectivement autorisée à accéder aux fichiers du compte du client.
Etablir cette autorisation, c’est le rôle d’OAuth.
Ce "protocole" fonctionne de la manière suivante :
-
il délégue au serveur de resource (hubic)
-
la tâche de demander au détenteur de resource (vous, moi)
-
d’autoriser ou non une application cliente (l’application qui veut interagir avec hubic)
-
de faire certains types d’opérations (les permissions sont clairement listées)
-
pour le compte du détenteur de resource (agir en votre nom)
-
sur les resources du détenteur (sur vos fichiers)
Pour être plus clair, une analogie :
-
si Jean demandait à son père la permission de jouer avec les légo de son frère Michel
-
le père répondait "je vais demander à Michel"
-
si Michel accepte, alors le père donnera à Jean un badge
-
Jean pourra jouer avec les légo de Michel s’il a son badge
-
Jean ne pourra pas jouer avec les petites voitures de Michel
-
et Jean ne pourra pas casser les légo de Michel (il ne peut que jouer)
-
de plus, Michel et son père peuvent confisquer le badge de Jean à tout moment
Dans la pratique, les permissions sont appelées scope, et notre application client_id. Si l’utilisateur accepte ces permissions, Hubic nous renvoie un "request token" appelé code :
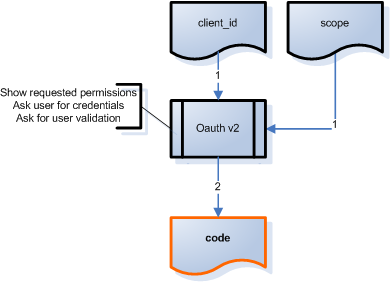
Ce code condense en une seule information, qui n’expire pas à moins d’être récusée, le fait qu’un utilisateur ait autorisé telle ou telle opération sur ses données. En conséquence, l’application pourra le stocker, l’associer à l’utilisateur, et l’utiliser au fur et à mesure des besoins.
Et selon l’analogie ci-dessus, le code reçu représente le badge que Jean a reçu.
En résumé, ce badge, en un seul objet simple, représente le fait que Jean a le droit :
-
de jouer
-
avec les légos
-
de Michel
Plutôt élégant non ?
Et on constate aussi qu’à aucun moment l’application n’a "vu" le mot de passe de l’utilisateur !
Demander un accès temporaire à l’API Hubic de l’utilisateur
Si je continue l’analogie, maintenant qu’on a un badge, on va certainement vouloir jouer avec les légos de Michel à un moment ou un autre.
Mais sous diverses formulations ("Michel et son père peuvent confisquer le badge de Jean à tout moment", que "ce code n’expire pas à moins d’être récusé") j’ai indiqué plus haut qu’une des grandes forces d’OAuth est de pouvoir retirer les autorisations à tout moment, et c’est ici que ça va se passer.
Et pour permettre ça, il n’y a pas pléthore de solutions : il faut contrôler chaque accès qui est fait.
Premier écueil technique, les performances … imaginons que vous ayez 10 millions de clients au total, et 20 clients simultanés. Pour chaque requête, il vous faudra rechercher le "code" de ces 20 utilisateurs dans l’intégralité de la base de 10 millions de clients. Ca risque de ramer.
La solution, comme d’habitude, c’est la mise en cache du résultat.
L’idée est donc de ne pas vérifier à chaque accès avec le code, mais plutôt de :
-
vérifier une fois le code de l’utilisateur
-
s’il est bon, générer un jeton d’accès (
access token) représentant le résultat -
associer à ce jeton d’accès une durée de vie représentant la durée de vie du résultat
-
stocker ce jeton d’accès et sa durée de vie dans base
-
chaque accès est toujours vérifié, mais via le jeton d’accès plutôt que le code
Les conséquences sont les suivantes :
-
l’opération "lourde" de validation du code n’est réalisée qu’une fois par durée de vie de jeton
-
la "petite" base de donnée de jetons ne contient "que" les jetons des requêtes récentes (environ 20 entrées au lieu de 10M)
Il devient très rapide et facile de vérifier les accès, sans impact sur les performances.
On conserve la possibilité de refuser les accès à tout moment :
-
en supprimant le code associé à l’utilisateur (pour empêcher la génération de novueaux jetons d’accès)
-
en supprimant le jeton d’accès "en cours" de la "petite" base de donnée de vérification des accès
C’est comme ça qu’on devient capables de contrôler l’accès à l’API.
Parce que oui, Hubic étant un sevrice accessible par une API, toutes les opérations se feront par cette API. En conséquence, avant d’utiliser l’API Hubic pour accéder au données du client, on utilise notre "code" de permission utilisateur pour obtenir de manière efficiente un accès à l’API Hubic.
C’est toujours le protocole OAuth (vu que c’est lui qui a fourni le code) qui va nous permettre de demander ce jeton temporaire pour accéder à l’API Hubic.
On fournit l’identification du "client" (notre application), on fournit le code de permission obtenu avant (qui est lié à cette application et à l’utilisateur), et on indique ce qu’on veut, c’est à dire qu’on nous donne ("grant") un jeton d’autorisation. Tout ça est visible sur la synthèse ci-après :
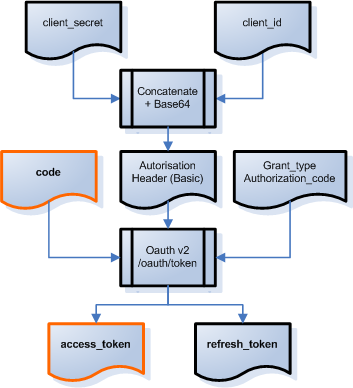
Cet appel nous retourne (sous forme JSON) :
-
access_token: un jeton jeton d’accès -
expires_in: sa durée de validité (ici, 21600 secondes) -
refresh_token: un jeton de renouvellement -
token_type=Bearer: le type de jeton d’accès ("bearer" = au porteur)
L’application peut maintenant stocker cet "access token" et l’utiliser pendant 6 heures pour faire des appels à l’API Hubic. C’est "comme si on utilisait directement le `code`", mais en permettant au service Hubic d’être bien plus performant.
Je ne vous ai pas parlé du jeton refresh_token : comme le jeton d’accès a une durée de vie limitée, il faudra en demander un autre. Deux possibilités : soit on demande un nouvel jeton en utilisant le code comme on vient de le faire, soit on utilise ce jeton de rafraichissement pour regénérer un nouveau jeton d’accès.
Laquelle choisir ? Réfléchissons : d’un côté, passer par le code revient à nouveau à consulter toute la base. Alors que comme il y a un jeton de rafraichissement par jeton d’accès en cours, et donc de "sessions" en cours, il est donc beaucoup plus rapide de passer par le jeton de rafraichissement que par le code pour renouveler le jeton d’accès.
Utiliser l’API Hubic … dans quel but ?
Grâce à ce jeton d’accès à l’API Hubic, on peut faire dans l’API Hubic toutes les opérations qui nous ont été autorisées :
-
récupérer les informations du compte via
/account -
récupérer les statistiques d’utilisation du compte via
/account/usage -
… et surtout, demander l’accès à l’API de stockage de fichier.
Quoi, il faut encore demander l’accès ?!
Et bien oui : l’API d’Hubic ça n’est pas "que" des fichiers, ça concerne aussi la gestion du compte, des liens partagés, du parainage, et tout ça est accessible par l’API d’Hubic.
En conséquence, la partie "stockage des fichiers" est une autre fonction, externe à l’API Hubic en elle même.
L’accès est contrôlée par la l’API Hubic /v1/account/credentials
-
on fournit le jeton d’accès à l’API qu’on a obtenu juste avant (et rafraichi en cas de besoin !)
-
on récupère un bout de JSON, qui contient entre autres un
tokenet unendpoint
Ca donne le schémas suivant :
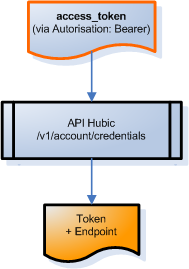
Si est pas totalement perdus, on se rend compte que … c’est exactement ce que retourne la première étape (authentification v1) de Swift, tout au début de cet article !
Et bien oui, après tout ce travail, on a récupèré de quoi faire un appel en Object Storage v1, et accéder pour de vrai au fichiers… Ouf !
On pourrait donc uploader/downloader/supprimer des fichiers de notre compte avec les outils Swifts, si seulement ils savaient gérer l’authentification complexe d’Hubic !
Synthèse
Après tout ça, après avoir vu chaque étape en détails, on tout réassembler, et dé-zoomer pour voir l’ensemble du processus :
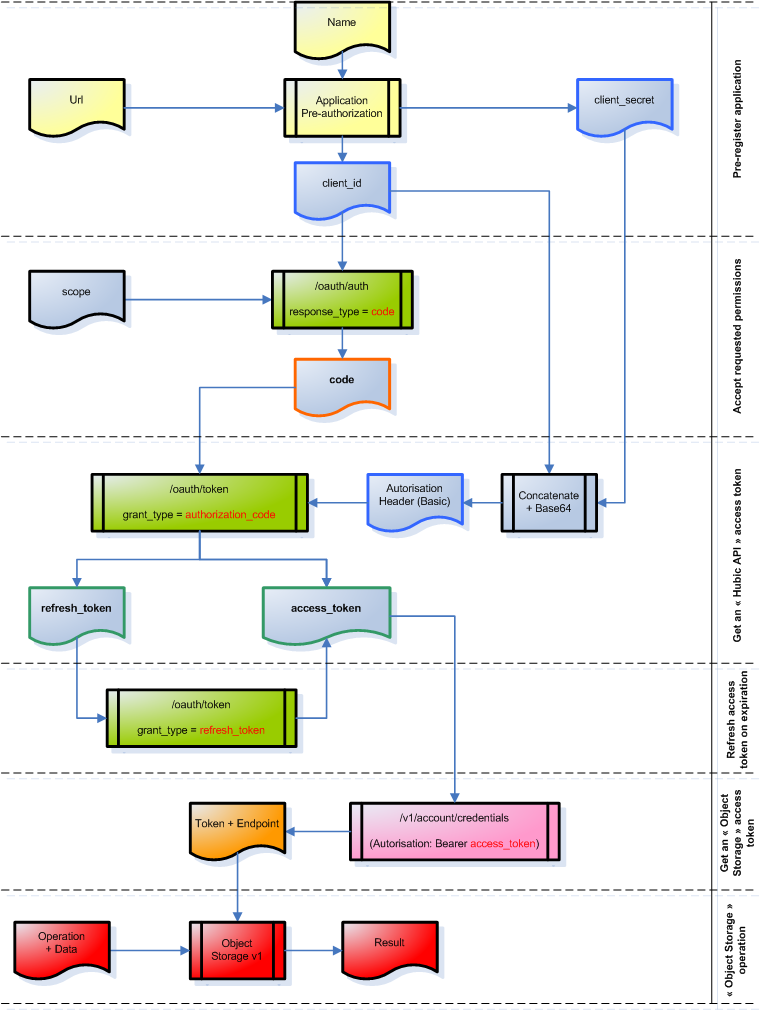
Impressionnant, non ?
La gateway Hubic/Swift
Quand on regarde le schémas ci-dessus, on peut condenser le jaune, le vert, et le rose en un seul bloc "bleu" qui résumererait l’authentification Hubic :
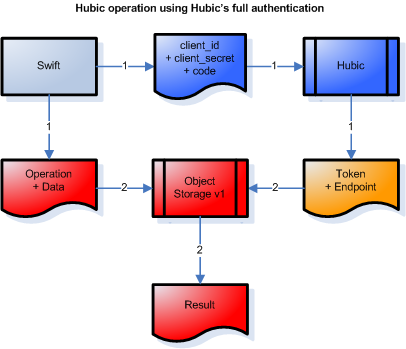
Et quand on compare avec le schémas Swift (Auth v1 + Object Storage v1) du début :
C’est quasiment pareil !
Et bien une "gateway Hubic/Swift", c’est "juste" un truc qui permet de "faire ce que contient le bleu" quand on utilise des outils qui ne sauraient que "faire du jaune". Ou dit différement, un truc qui fait que Swift et ses copains, ne voient pas tout ce qui est caché par le bleu, et qui vu de l’extérieur leur semble être du jaune.
C’est tout. Plutôt classe, non ?